Thrive Development Forum
CPA Prototype
Theory
tjwhale
February 29, 2016, 3:49pm
13
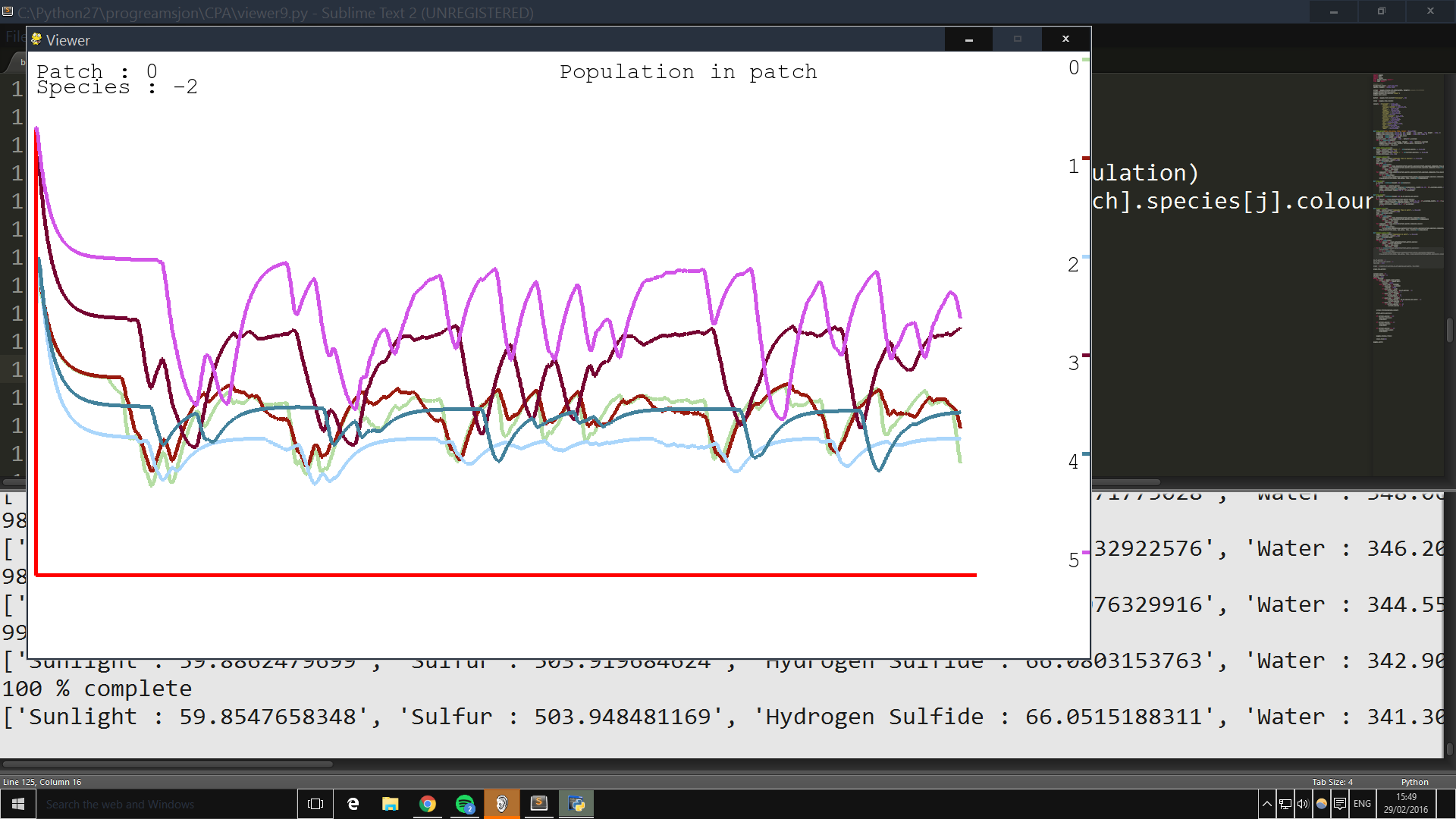
This is what it looks like with bacteria processing spilled compounds !!! HYPE!
Pasted image
1920×1080 100 KB
1 Like
show post in topic